ELU, also know as Exponential Linear Unit is an activation function which is somewhat similar to the ReLU with some differences. Similar to other non-saturating activation functions, ELU does not suffer from the problem of vanishing gradients and exploding gradients. And similar to Leaky-ReLU and PReLU, and unlike ReLU, ELU does not suffer from the problems of dying neurons. It has proven to be better than ReLU and its variants like Leaky-ReLU(LReLU) and Parameterized-ReLU(PReLU). Using ELU leads to a lower training times and and higher accuracies in Neural Networks as compared to ReLU, and its variants.
ELU activation function is continuous and differentiable at all points. For positive values of input x, the function simply outputs x. Whereas if the input is negative, the output is exp(z) – 1 . As input values tend to become more and more negative, the output tends to be closer to 1. The derivative of the ELU function is 1 for all positive values and exp(x) for all negative values. Mathematically, the ELU activation function can be written as-
y = ELU(x) = exp(x) − 1 ; if x<0
y = ELU(x) = x ; if x≥0
The graph for the ELU function, is shown below-
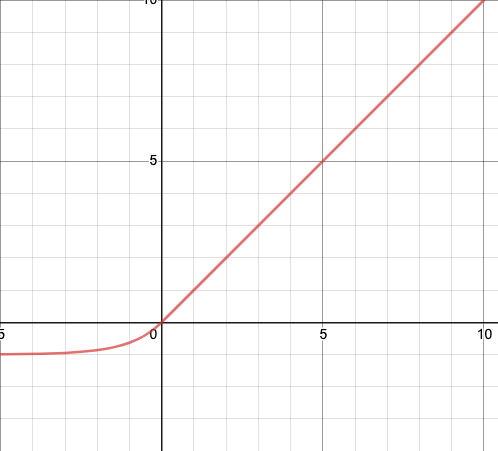
Unlike ReLU, ELU’s have a negative value too which cause the mean of the ELU activation function to shift towards 0. The research paper that first introduced ELU’s argue that due to this shift, the training of the model converges faster than other activation functions. Despite it being slower to compute the ELU function, this faster convergence allows model to train faster than ReLU and its variants. Along with this, they have better generalized performance and hence better accuracy than ReLU and its variants.
Pros
- It is continuous and differentiable at all points.
- It is leads to faster training times as compared to other linear non-saturating activation functions such as ReLU and its variants.
- Unlike ReLU, it does not suffer from the problem of dying neurons. This because of the fact that the gradient of ELU is non-zero for all negative values.
- Being a non-saturating activation function, it does not suffer from the problems of exploding or vanishing gradients.
- It achieves higher accuracy as compared to other activation functions such as ReLU and variants, Sigmoid, and Hyperbolic Tangent.
Cons
- It is slower to compute in comparison to ReLU and its variants because of the non-linearity involved for the negative inputs. However, during the training times, this is more than compensated by the faster convergence of ELU. But during the test time, ELU will perform slower than ReLU and its variants.