One question that frequently comes in the mind of people getting started in the field of Machine Learning is “What matters more- data or the choice of algorithm?”. More specifically what is the effect of having more training data on different algorithms?, how does the accuracy of various algorithms change when provided with more data.
A study of this kind was conducted by two Microsoft scientists, Michele Banko and Eric Brill in the year 2001. Their paper “Scaling to Very Very Large Corpora for Natural Language Disambiguation” can be found over here. They studied how different algorithms performed on a very complex complex problem of Natural Language Disambiguation once they are provided with more and more data. The graph below is from the original paper, it shows how the test accuracy(on the vertical axis) of different algorithms varies with training data(on the horizontal axis- in millions of words).
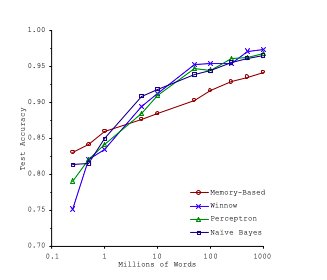
In the graph it can be clearly seen that all algorithms including very simple algorithms start to perform very well at the task once they have been provided with sufficiently high training data. The researchers further proposed that the research community should direct efforts towards increasing the size of the annotated training collections, while de-emphasising the focus on comparing different learning techniques trained only on small training data/corpora.
Another study was conducted in this field by Peter Norvig and others in a paper titled “The Unreasonable Effectiveness of Data” published in 2009. The paper takes forward the idea that size of the training data matters more than algorithms. The paper explicitly states the importance of data over algorithm as- “simple models and a lot of data trump more elaborate models based on less data”.
A study conducted by James Hays and Alexei A. Efros in a paper titled “Scene completion using millions of photographs” compared how the accuracy of models varied over the size of training data. They concluded that when using a training set of a thousands of photos the results were poor but once they had a training set of millions of photos, the same algorithms performed very well.
It would therefore seem quite logical to dump the use of complex algorithms and move to making use of larger datasets. However it should be noted that it is not always cheap and feasible to get more data. Most of the datasets available even nowadays are small and medium sized. It is due to these conditions that in practical scenarios the choice of algorithms still matter.