In the last blog post, we talked about noisy student algorithm. In this blog, we will be talking about how to get the best results out of noisy student training. This blog post will talk about various trials conducted in the original research by researchers at Google and CMU, and what worked best for them. This, however, does not guarantee that all of these techniques will work for you. You can, however, use this blog as a reference and see for yourself which techniques work the best for you.
Large Teacher Model
Using a large teacher model that has a higher accuracy leads to better results when using noisy student training. A possible reason for this can be that a larger teacher model with higher accuracy will be able to predict the pseudo labels more accurately than a smaller model with lower accuracy. The accuracy of pseudo labels does play an important part in noisy student training. A large number of incorrect labels will make the student model learn the wrong class for the images. Hence, bringing down the accuracy of the student model.
Un-labeled Dataset Size
A large un-labeled dataset leads to better accuracy of the student model. This large amount of un-labeled dataset helps the student model learn from more images. A large un-labeled dataset will also help the model generalize better to and avoid overfitting during training.
Using soft Pseudo Labels
Using soft pseudo labels, which are continuous probability distributions has shown to improve the accuracy of the student model more than the use of hard pseudo labels, which are one hot distributions. Another added advantage that comes with the use of soft pseudo labels is that it can be used to filter data. Filtering data on which the teacher model has low confidence can be used to improve the accuracy of pseudo labels. While at the same time it helps to address the class imbalance problem.
Large Student Model
Using a large student model has shown to improve the accuracy of the student model when using with noisy student training. A large student model will have more capacity to learn from data and hence ‘expand’ the knowledge domain of the teacher model.
Data Filtering
Employing data filtering when training with noisy student has shown to improve the accuracy of models. Specifically, the images from the un-labeled dataset for which the teacher model has low confidence are filtered out.
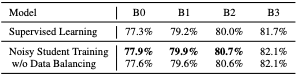
Data Balancing
Data balancing refers to balancing the number of images that belong to each class. Ideally, the distribution of images in an un-labeled dataset should match that of the labeled dataset. The research was conducted on ImageNet dataset that contains a total of 1000 classes, where all classes have an equal representation. Hence, the un-labeled dataset was balanced to match the same distribution. In un-labeled dataset, each class had 130K images. Data filtering(for classes with abundant images) and Image duplication(for classes that did not have a sufficient number of images) were used for data balancing. Data balancing is especially more helpful when the model being trained is small(not smaller than the teacher model).
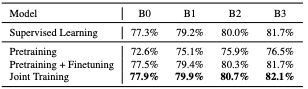
Training Methodology
Training a student jointly on labeled and un-labeled data leads to higher accuracy. Comparatively, training a student on un-labeled data followed by fine-tuning it on the labeled data leads to lower accuracy.
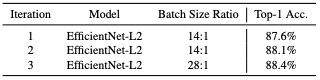
Batch Size Ratio
A large ratio between the batch size of un-labeled data and the labeled data leads to higher accuracy of the student model. A Bigger batch size of un-labeled data enables the student model to train for much longer and more examples.
Training the student from Scratch
Training the student model from scratch sometimes leads to better results as compared to initializing the student with the teacher model. So, instead of initializing the student with the teacher model and then tweaking its parameters during training, building a model from scratch might lead to higher accuracy. This technique however does not work at all times. Hence it might be best to see it for yourself if this technique works for your model. However, contrary to expectations, initializing the student with the teacher model does not drastically decrease the computation required to train the student model. It still takes a large number of epochs to train the student after initializing with the teacher model.

Iterative Training
Iterative training is when the student model is made the new teacher, which then trains a new student model. Using Iterative training helps in improving accuracy when using noisy student training. The improvement in accuracy however fades over iterations. The accuracy of the new student model does improve very much after a given number of iterations. The exact number of times iterative training will improve the accuracy of the student model has to be determined empirically.
Adding Noise
Adding noise to the student model via dropout and stochastic depth and to the data via data augmentation while training the student model leads to an increase in the accuracy. The accuracy of the student model decreases consistently with the reduced and eventually removed noise. Also of importance here is to talk about the importance of un-noised teacher model when generating pseudo-labels. The addition of noise to the teacher model during pseudo-label generation leads to a decreased accuracy.