In one of my recent posts, I talked about pretext training, in which the Machine Learning model is trained to perform an upstream task prior to being trained on the actual, downstream task. This helps in reducing the amount of labeled data required to train a model and is used widely for Self Supervised Learning. You can read that blog post over here. In this blog post, I will be talking about some of the techniques you can use for pretext training for your computer vision models.
Predicting Image Rotations
You can make your model learn meaningful representations about the data by training them to predict the amount of rotation of images. You rotate the images randomly by 0, 90, 180, or 270 degrees and make the model predict the amount of rotation, making it a classification problem. This technique was first suggested by Gidaris et al. in their paper submitted at the International Conference of Learning Representations(ICLR), 2018. You can check out the paper here.
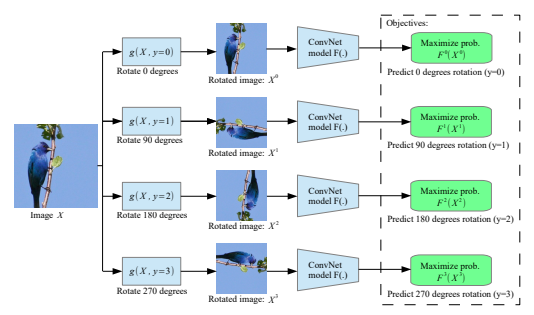
Predicting Relative Position of Image Patches
Making your Neural Network predict the relative position of patches extracted at random from the same image can help your model learn the objects, their components, and their relative positions. This was first suggested by Doersch et al. in their 2015 paper “Unsupervised Visual Representation Learning by Context Prediction”. You can check out the paper here.
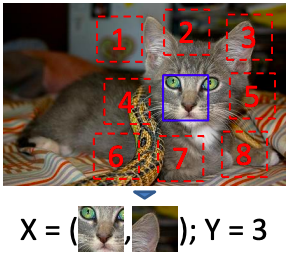
From an image, 2 random patches are extracted and the model is trained to predict the position of the second patch relative to the first patch. Considering the example of the above image, say we want to predict the position of the image patch at position 3 relative to the first image patch bounded by the blue box. There are a total of 8 positions the second image patch can have relative to the first one. However, the correct position would be at position 3. This problem is also a classification problem.
Image Inpainting
Image Inpainting refers to creating/recreating an area of an image that has been removed. From an image, a part of the image is removed and the model is trained to recreate the removed part of the image. This helps the model to learn about the context of the entire image and an understanding of the missing part. This technique, therefore, requires a very good understanding of the features. This technique by proposed by Pathak et al. in their 2016 paper. You can check out their paper here. This technique is a generative method, which means that the model is trained to generate information in order to learn the features of the image. The image below shows the results of Image Inpainting.

Colorization
Colorization refers to creating a color image from a grayscale image. The neural network is provided with a grayscale(black and white image) and is trained to color the image. In their 2016 paper, Zhang et al. proved that Colorization can be a powerful pretext task for Self Supervised feature learning. Models that were trained for Colorization performed well on classification, detection, and segmentation as well when compared to other Self-Supervised Pretext training tasks. You can check out their paper here. The image below shows the results of colorizing grayscale image. Like Image Inpainting, this technique is a generative method as well.

References
The paper- Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey. To read, click here.