In my previous blog post, I showed how you can implement Image Rotation Pretext Training to perform Self Supervised Learning using Keras. You can check out that blog post here. This blog post will be a follow-up to my last blog post. In this blog post, I will compare how the model that we trained first on a pretext task before training it on the final downstream task compares to the model that will only be trained on the same dataset by supervised learning.
If you have an understanding of building and training Neural Networks in Keras, you are good to follow along with this blog post. Else, you can check out my blog on creating and training a Convolutional Neural Network to classify images of handwritten numbers(MNIST) here. This example should be sufficient for you to get the basics right and follow along with this blog post.
We will train a Neural Network with the same architecture and train it on the same data used in the last blog post to train the network on the final downstream task and compare how both the models fare against each other. For reference, the model that was trained on the pretext training before training on the final downstream task had an accuracy of 84.32%.
Importing Libraries
What’s the first thing we do before we begin to code? That’s right! Import all the necessary libraries. So let’s do that first.
# Importing Libraries
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import kerasLoading Data
Since we will be using the same dataset for training a modle with the same architecture as we did in the previous blog, we will use the Fashion MNIST Dataset. We will load the dataset by using the API provided by Keras.
data=keras.datasets.fashion_mnist
# Getting the data
(X_train, y_train), (X_test, y_test) = data.load_data()Data Preprocessing and Splitting
It is important to preprocess the dataset and split it into Training(X_train, y_train), Validation(X_val, y_val), and Testing Dataset(X_test, y_test).
# Normalizing the dataset
X_train = X_train/255
X_test = X_test/255
# Splitting the test dataset into validation and test dataset
X_val = X_test[:5000]
y_val = y_test[:5000]
X_test = X_test[5000:]
y_test = y_test[5000:]Since we used only the first 10,000 images in the previous example, in this example too, out of the total training dataset, we will select only the first 10,000 images.
# Selecting first 10,000 images to train the Network
X_train=X_train[:10000]
y_train=y_train[:10000]Training a Convolutional Neural Network
The next step will be to build and train a Convolutional Neural Network with the same architecture as in the previous blog post.
# Creating a Convolutional Neural Network
model = keras.models.Sequential([
keras.layers.Conv2D(64, 7, activation="relu", padding="same",
input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(4, activation="softmax")
])Next, we compile the model. While compiling, we set the loss function to Sparse Categorical Cross-Entropy and the Optimizer to Stochastic Gradient Descent.
# Compiling the model
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])The inputs need to be reshaped so that their shape is the same as expected by the Neural Network.
X_test=X_test.reshape(-1, 28, 28, 1)
X_val=X_val.reshape(-1, 28, 28, 1)
X_train=X_train.reshape(-1, 28, 28, 1)Finally, let’s train our Convolutional Neural Network by Supervised Learning. We call the fit() method and pass to it the training and validation datasets. The training loop turns for 10 epochs as we did for the downstream task in the last blog post.
# Training the CNN model
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_val, y_val))
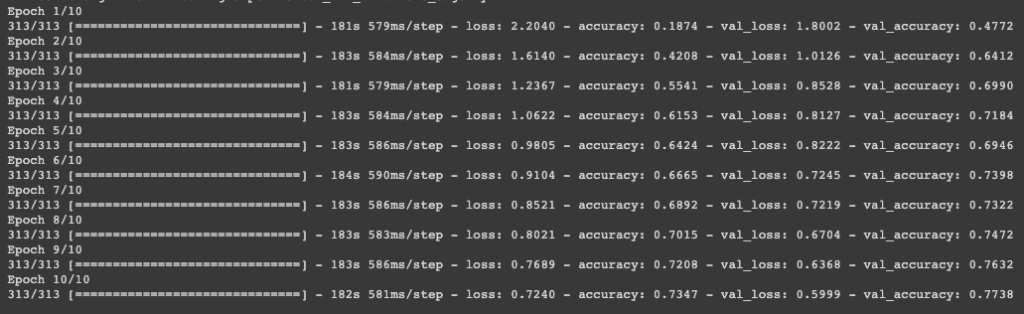
The image below shows how the training and validation losses and accuracy fare over various epochs.
Finally, we evaluate the accuracy of the model on the test dataset.
# Evaluating the model on the Test set
model.evaluate(X_test, y_test)The accuracy of the model on the test dataset for this particular example at the time of doing it was found to be 76.40%.

Comparing to Supervised Learning to Self Supervised Learning
The model that is trained by using pretext learning tasks such as predicting Image Rotation performs better at the downstream task as compared to a model that is solely trained on the downstream task by using Supervised Learning. The model trained on the Pretext Training task achieved an accuracy of 84.32% on the task as compared to 76.40% by the model trained on only the actual downstream task. However, that is not all, take a look at the accuracy of the model pre-trained on pretext task varies over various epochs-
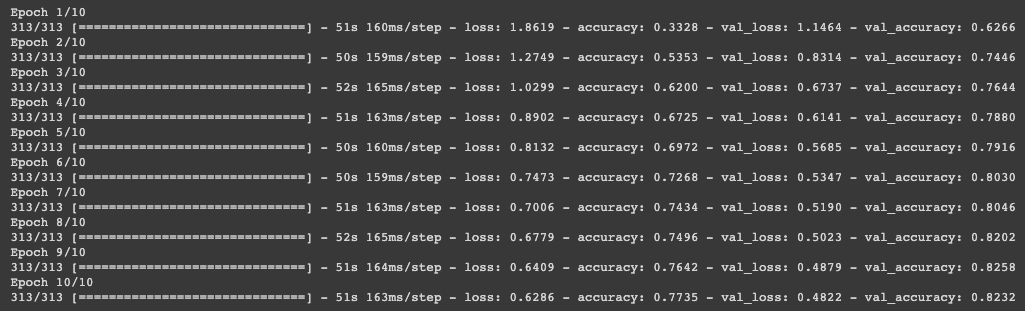
After comparing the accuracies over various epochs, you will see that not only does the model pre-trained on pretext tasks perform better overall, but also it learns quicker as compared to the model that is trained only on the actual downstream task. Say, for example, if you consider only the validation accuracy of the model after the first epoch, the model that is pre-trained on pretext task has an accuracy of 62.66%, which is much higher than 47.72% as compared to the model that is only trained on the actual downstream task.
The chart below compares the accuracies of both models trained using different approaches over various epochs.
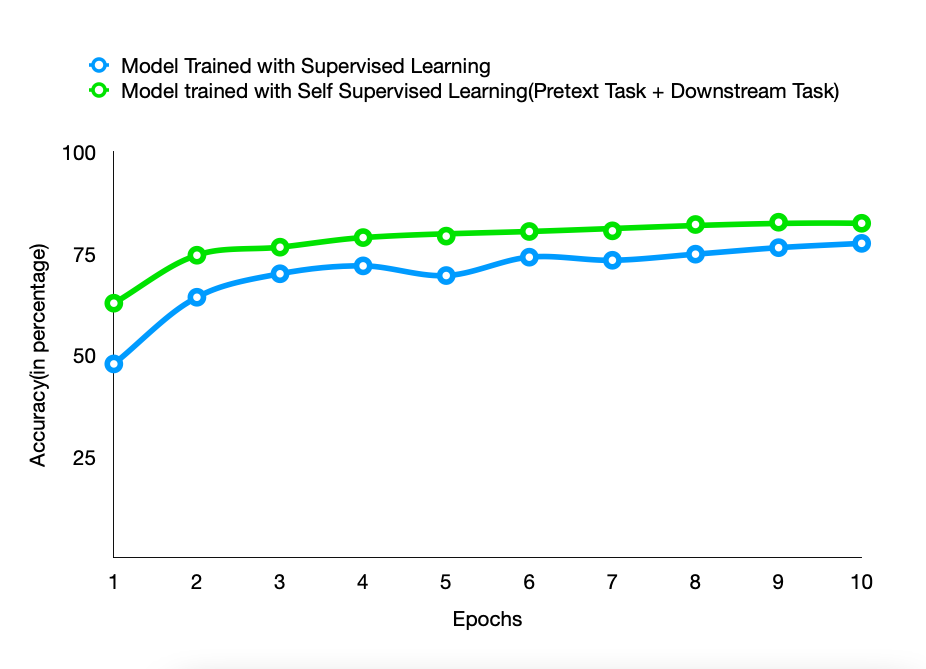
As it can be clearly seen, the model that is trained with Self Supervised Learning performs better than that trained with Supervised Learning and the difference is even greater as the labeled data(the number of epochs) becomes less. This finding seems to validate the known truth about Self Supervised Learning.