Transformers first appeared in the context of Natural Language Processing tasks. They Natural Language transformers gained upper hand over Convolutional Neural Networks(CNNs) and Recurrent Neural Networks(RNNs). The massive success of Transformers in the field of Natural Language such as GPT-2, GPT-3, BERT, and RoBERTa lead to an ever increasing interest in Vision Transformers. Vision Transformers such as ViT demonstrated their superiority in the field of Image Classification by beating state-of-the-art Convolutional Neural Networks or ConvNets. However, at the same time, they suffer from poor accuracy at other Computer Vision tasks such as Object Detection and Semantic Segmentation. In this blog post, we will cover a paper titled- A Convnet for the 2020s. The paper dives into gradual improvement of Convolutional Neural Networks and demonstrate their superiority over Vision Transformers. The authors also propose a new improved CNN which they refer to as ConvNext. This paper is from Facebook AI Research(FAIR). and has had support from Yann LeCun- one of the prominent figures in the Computer Vision and Machine Learning space.
Vision Transformers such as ViT has a global attention design which has a Quadratic time complexity with respect to input size. This result is the Vision Transformers cannot be scaled up to much higher resolutions. Besides, Transformers also do not have the design simplicity of ConvNets.
The paper has had support from Yann LeCun- one of the most prominent figures in the Computer Vision and Machine Learning space. So I know this is going to be a very interesting paper. Without wasting any more time let’s get started.
About ConvNext
Residual Networks such as ResNets have long been used in the field of Computer Vision. Their architecture consisting of smaller Residual Block makes it much easier to train a deep neural network by using skip connections. Due to their wild success, ResNet will be the starting point. From this starting point gradual improvements will be made to the network to improve it and after each improvement, its performance will be measured on the dataset and also compared to vision transformers.
The paper asks a critical question about comparison between vision transformers and ConvNets-
How do design decisions in Transformers impact ConvNets’ performance?
Throughout the paper, the authors make changes to the basic ResNet ConvNet and change its design and training to match that of a Vision Transformer and see how each change affects the accuracy and performance of the model.
The Result?
ConvNext: A ConvNet which has the design simplicity of Convolutional Neural Networks while having better accuracy, performance and scalability than Vision Transformers.
Modernization of ConvNet
This section takes you on a deep dive of the design decisions of Vision Transformers, and then trying to replicate those in a basic ResNet-50 ConvNet. The effects of various changes to the ConvNet is also discussed.
Training Technique
The method for training a Neural Network plays a huge role in the performance of a Neural Network. Vision Transformers also introduced new training techniques such as use of AdamW Optimizer, Data Augmentation, etc. The following changes were made to the training of the ResNet-50 Neural Network-
- Increasing the number of epochs during training from 90 to 300.
- Use of AdamW Optimizer.
- Use of various Data Augmentation techniques such as Mixup, CutMix, RandAugment, and RandomErasing.
- Use of Regularization Schemes such as Stochastic Depth, and Label Smoothing.
These changes in the training technique lead to an increase in the accuracy of the ResNet from an original 76.1% to 78.8%
Going forward, this training method will be used for training the network as more changes are made to the architecture of the network.
Macro Design
The following design considerations were made in response to analyzing of Swin Transformers-
Changing Stage Compute Ratio
Swin Transformers follow as stage compute ratio of 1:1:3:1 for smaller transformers and 1:1:9:1 for larger transformers. Following the same change in design, the number of blocks in each stage were change from (3, 4, 6, 3) to (3, 3, 9, s3).
These changes in the macro design lead to a further increase in the accuracy from 78.8% to 79.4%, an increase of 0.6%.
Changing Stem to Patchify
The stem cell was replaced with a patchify layer with 4*4 stride 4 Convolutional Layer.
This further increased the accuracy from 79.4% to 79.5%, an increase of 0.1%.
Going forward, only the (3, 3, 9, s3) stage ratio will be used and patchify will be used in place of stem.
ResNext-ify
The ResNext family of Convolutional Neural Networks are similar to ResNet. However, ResNext have which has a better FLOPs/accuracy trade-off than ResNets. The primary reason for this is that the convolutional filters are split into different groups. Similar to s Swin Transformer which uses 96 channels, the width of the ResNet is expanded from 64 channels to 96 channels.
This increases the accuracy from 79.5% to 80.5%, albeit with higher FLOPs.
Inverted Bottleneck
Every Transformer block contains a bottleneck, i.e, the hidden dimension of the MLP block is four times wider than the input dimension. This same idea was popularized by the MobileNetV2 and has been used in various Neural Network architectures since then.
The use of inverted bottleneck results in a slight improve in performance from 80.5% to 80.6%.
Large Kernel Size
Moving Up Depth-Wise Conv Layer
A trade of for using large kernels is that the position of the depth-wise convolution layer need to be moved up. That is also similar to what happens in a Transformer.
This change leads to a decrease in the accuracy from 80.6% to 79.9%, a decrease of 0.7%.
Increase Kernel Size
A large kernel size is generally beneficial for increasing the accuracy of the model. The following kernel sizes were tried- 3*3, 5*5, 7*7, 9*9, and 11*11. Among these, the 7*7 kernel size lead to the greatest increase in the model accuracy while keeping the FLOPs same. Any further increase in kernel size does not lead to any significant increase in the accuracy.
The change of kernel size from 3*3 to 7*7 leads to an increase in the accuracy from 79.9% to 80.6%, an increase of 0.7%.
Micro Design
The following micro design changes(changes at the level of the layer) were made to the ResNet to bring it at par with vision transformers.
Replacing ReLU with GeLU
ReLU is one of the most commonly used activation function, especially in the field of Computer Vision. However, Transformers use the Gaussian Error Linear Unit or GELU– a smoother version of ReLU, activation function.
Going forward, all GELU will replace all the RELU activation functions in the Neural Network.
The use of GELU in place of RELU has no effect on the accuracy.
Fewer Activation Functions
Transformers have fewer activation function than ResNets. To replicate the same in ConvNets, all GELU layers are eliminated from the residual block except for one between two 1 × 1 layers.
This results in an increase in the accuracy from 80.6% to 81.3%, an increase by 0.7%.
Fewer Normalization Layers
Vision Transformers have fewer normalization layers. Therefore, two BatchNorm or BN layers are removed, leaving only one BN layer before the 1 × 1 Convolutional layers.
This increases the accuracy from 81.3% to 81.4%, an increase of 0.1%.
Substituting BN with LN
Batch Normalization or BN Layers reduce overfitting and speeds up the convergence process. Sometimes however, BN Layers have the opposite of effect. Transforms use Layer Normalization or LN Layers in place of BN Layers.
The use of LN in place of BN increase accuracy from 81.4% to 81.5%, an increase of 0.1%.
Separate Downsampling Layers
Swin Transformers use a separate downsampling layer which is added between stages. A similar change was employed in which 2×2 conv layers with stride 2 for spatial downsampling was used.
This lead to an increase in the accuracy from 81.5% to 82%.
After making all these changes, we finally have a new Convolutional Neural Network, the ConvNext.
Summary of ConvNext
The Table below summarized the various changes which were made to the original ResNet-50 in the effort to modernize it. The table also contains the value of accuracy after implementing the change and the how much it has changed as compared to last change.
| Change | Accuracy after implementing | Change |
|---|---|---|
| Basic Resnet-50 | 76.1% | – |
| Changing Training Technique | 78.8% | +2.7% |
| Changing Stage Compute Ratio | 79.4% | +0.6% |
| Changing stem to patchify | 79.5% | +0.1% |
| ResNext-ify | 80.5% | +1.0% |
| Inverted Bottleneck | 80.6% | +0.1% |
| Moving up depth-wise Conv layer | 79.9% | -0.7% |
| Increasing the Kernel size | 80.6% | +0.7% |
| Replacing ReLU with GELU | 80.6% | +0.0% |
| Fewer Activation Functions | 81.3% | +0.7% |
| Fewer Normalization Layers | 81.4% | +0.1% |
| Substituting BN with LN | 81.5% | +0.1% |
| Seperate Downsampling Layers | 82.0% | +0.5% |
Evaluation of ConvNext
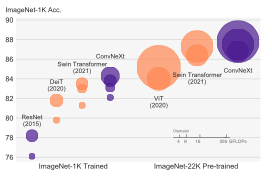
The new ConvNet which is dubbed as ConvNext does not only have higher accuracy as compared to their vision transformer counterparts but is also more scalable.
The graph below shows how ConvNext models compare with their vision transformer counterparts.
Conclusion
After making all the changes, the accuracy of the newly designed ConvNet surpasses that of Vision Transformer while maintaining the simplicity of ConvNet. Additionally, the newly designed ConvNet is more scalable than a Vision Transformer. ConvNext is similar to any other ConvNet in the sense that no new design is implemented. All the design decisions implemented in ConvNext have been researched individually but not collectively. The paper just brings together these individually researched topics and makes design decisions for a ConvNet based it.
Also Read
Comparing Models trained on Pretext Task to Supervised Learning Models
Implementing Image Rotation Pretext Training for Self Supervised Learning using Keras
What is Self Supervised Learning and Why is everyone talking about it?
Pretext Training Tasks for Self Supervised Learning in Computer Vision